
Dimensionality Reduction
Contents
![]()
Dimensionality Reduction¶
Objectives¶
In this notebook you will explore the application of Principal Components Analysis (PCA) to multivariate data. Throughout the notebook, you will work with projecting the activity of two neurons (data in two dimensions) onto it’s “principal components” (the eigenvectors of its covariance matrix; ie a new basis).
Overview:
Perform PCA (get the eigenvectors of the activity of two neurons).
Plot and explore the variance of the data explained in each dimension (ie the eigenvalues).
Setup¶
#@title {display-mode: "form"}
#@markdown Execute this cell to specify Imports and Functions
# Imports
import numpy as np
import matplotlib.pyplot as plt
# Figure Settings
import ipywidgets as widgets # interactive display
%config InlineBackend.figure_format = 'retina'
plt.style.use("https://raw.githubusercontent.com/NeuromatchAcademy/course-content/master/nma.mplstyle")
# Plotting Functions
def plot_eigenvalues(evals):
"""
Plots eigenvalues.
Args:
(numpy array of floats) : Vector of eigenvalues
Returns:
Nothing.
"""
plt.figure(figsize=(6, 4))
plt.plot(np.arange(1, len(evals) + 1), evals, 'o-k')
plt.xlabel('Component')
plt.ylabel('Eigenvalue')
plt.title('Scree plot')
plt.xticks(np.arange(1, len(evals) + 1))
plt.ylim([0, 2.5])
def plot_data(X):
"""
Plots bivariate data. Includes a plot of each random variable, and a scatter
scatter plot of their joint activity. The title indicates the sample
correlation calculated from the data.
Args:
X (numpy array of floats) : Data matrix each column corresponds to a
different random variable
Returns:
Nothing.
"""
fig = plt.figure(figsize=[8, 4])
gs = fig.add_gridspec(2, 2)
ax1 = fig.add_subplot(gs[0, 0])
ax1.plot(X[:, 0], color='k')
plt.ylabel('Neuron 1')
ax2 = fig.add_subplot(gs[1, 0])
ax2.plot(X[:, 1], color='k')
plt.xlabel('Sample Number (sorted)')
plt.ylabel('Neuron 2')
ax3 = fig.add_subplot(gs[:, 1])
ax3.plot(X[:, 0], X[:, 1], '.', markerfacecolor=[.5, .5, .5],
markeredgewidth=0)
ax3.axis('equal')
plt.xlabel('Neuron 1 activity')
plt.ylabel('Neuron 2 activity')
plt.title('Sample corr: {:.1f}'.format(np.corrcoef(X[:, 0], X[:, 1])[0, 1]))
plt.show()
def plot_data_new_basis(Y):
"""
Plots bivariate data after transformation to new bases. Similar to plot_data
but with colors corresponding to projections onto basis 1 (red) and
basis 2 (blue).
The title indicates the sample correlation calculated from the data.
Note that samples are re-sorted in ascending order for the first random
variable.
Args:
Y (numpy array of floats) : Data matrix in new basis each column
corresponds to a different random variable
Returns:
Nothing.
"""
fig = plt.figure(figsize=[8, 4])
gs = fig.add_gridspec(2, 2)
ax1 = fig.add_subplot(gs[0, 0])
ax1.plot(Y[:, 0], 'r')
plt.ylabel('Projection \n basis vector 1')
ax2 = fig.add_subplot(gs[1, 0])
ax2.plot(Y[:, 1], 'b')
plt.xlabel('Sample number')
plt.ylabel('Projection \n basis vector 2')
ax3 = fig.add_subplot(gs[:, 1])
ax3.plot(Y[:, 0], Y[:, 1], '.', color=[.5, .5, .5])
ax3.axis('equal')
plt.xlabel('Projection basis vector 1')
plt.ylabel('Projection basis vector 2')
plt.title('Sample corr: {:.1f}'.format(np.corrcoef(Y[:, 0], Y[:, 1])[0, 1]))
plt.show()
def plot_basis_vectors(X, W):
"""
Plots bivariate data as well as new basis vectors.
Args:
X (numpy array of floats) : Data matrix each column corresponds to a
different random variable
W (numpy array of floats) : Square matrix representing new orthonormal
basis each column represents a basis vector
Returns:
Nothing.
"""
plt.figure(figsize=[4, 4])
plt.plot(X[:, 0], X[:, 1], '.', color=[.5, .5, .5])
plt.axis('equal')
plt.xlabel('Neuron 1 activity')
plt.ylabel('Neuron 2 activity')
plt.plot([0, W[0, 0]], [0, W[1, 0]], color='r', linewidth=3,
label='Basis vector 1')
plt.plot([0, W[0, 1]], [0, W[1, 1]], color='b', linewidth=3,
label='Basis vector 2')
plt.legend()
plt.show()
# Helper Functions
def sort_evals_descending(evals, evectors):
"""
Sorts eigenvalues and eigenvectors in decreasing order. Also aligns first two
eigenvectors to be in first two quadrants (if 2D).
Args:
evals (numpy array of floats) : Vector of eigenvalues
evectors (numpy array of floats) : Corresponding matrix of eigenvectors
each column corresponds to a different
eigenvalue
Returns:
(numpy array of floats) : Vector of eigenvalues after sorting
(numpy array of floats) : Matrix of eigenvectors after sorting
"""
index = np.flip(np.argsort(evals))
evals = evals[index]
evectors = evectors[:, index]
if evals.shape[0] == 2:
if np.arccos(np.matmul(evectors[:, 0],
1 / np.sqrt(2) * np.array([1, 1]))) > np.pi / 2:
evectors[:, 0] = -evectors[:, 0]
if np.arccos(np.matmul(evectors[:, 1],
1 / np.sqrt(2) * np.array([-1, 1]))) > np.pi / 2:
evectors[:, 1] = -evectors[:, 1]
return evals, evectors
def get_data(cov_matrix):
"""
Returns a matrix of 1000 samples from a bivariate, zero-mean Gaussian
Note that samples are sorted in ascending order for the first random
variable.
Args:
var_1 (scalar) : variance of the first random variable
var_2 (scalar) : variance of the second random variable
cov_matrix (numpy array of floats) : desired covariance matrix
Returns:
(numpy array of floats) : samples from the bivariate Gaussian,
with each column corresponding to a
different random variable
"""
mean = np.array([0, 0])
X = np.random.multivariate_normal(mean, cov_matrix, size=1000)
indices_for_sorting = np.argsort(X[:, 0])
X = X[indices_for_sorting, :]
return X
def calculate_cov_matrix(var_1, var_2, corr_coef):
"""
Calculates the covariance matrix based on the variances and
correlation coefficient.
Args:
var_1 (scalar) : variance of the first random variable
var_2 (scalar) : variance of the second random variable
corr_coef (scalar) : correlation coefficient
Returns:
(numpy array of floats) : covariance matrix
"""
cov = corr_coef * np.sqrt(var_1 * var_2)
cov_matrix = np.array([[var_1, cov], [cov, var_2]])
return cov_matrix
def define_orthonormal_basis(u):
"""
Calculates an orthonormal basis given an arbitrary vector u.
Args:
u (numpy array of floats) : arbitrary 2D vector used for new basis
Returns:
(numpy array of floats) : new orthonormal basis columns correspond to
basis vectors
"""
u = u / np.sqrt(u[0] ** 2 + u[1] ** 2)
w = np.array([-u[1], u[0]])
W = np.column_stack((u, w))
return W
def change_of_basis(X, W):
"""
Projects data onto a new basis.
Args:
X (numpy array of floats) : Data matrix each column corresponding to a
different random variable
W (numpy array of floats) : new orthonormal basis columns correspond to
basis vectors
Returns:
(numpy array of floats) : Data matrix expressed in new basis
"""
Y = np.matmul(X, W)
return Y
def get_sample_cov_matrix(X):
"""
Returns the sample covariance matrix of data X
Args:
X (numpy array of floats) : Data matrix each column corresponds to a
different random variable
Returns:
(numpy array of floats) : Covariance matrix
"""
# Subtract the mean of X
X = X - np.mean(X, 0)
# Calculate the covariance matrix (hint: use np.matmul)
cov_matrix = 1 / X.shape[0] * np.matmul(X.T, X)
return cov_matrix
def pca(X):
"""
Performs PCA on multivariate data.
Args:
X (numpy array of floats) : Data matrix each column corresponds to a
different random variable
Returns:
(numpy array of floats) : Data projected onto the new basis
(numpy array of floats) : Vector of eigenvalues
(numpy array of floats) : Corresponding matrix of eigenvectors
"""
# Calculate the sample covariance matrix
cov_matrix = get_sample_cov_matrix(X)
# Calculate the eigenvalues and eigenvectors
evals, evectors = np.linalg.eigh(cov_matrix)
# Sort the eigenvalues in descending order
evals, evectors = sort_evals_descending(evals, evectors)
# Project the data onto the new eigenvector basis
score = change_of_basis(X, evectors)
return score, evectors, evals
Section 1: What does PCA do?¶
In the last tutorial (Geometric View of Data) you explored what it means to project/transform multivariate data onto a new basis set (ie dimensions).
The goal of PCA is to find an orthonormal basis set that captures the maximum variance of the data possible. More precisely, the \(i\)th basis vector is the direction that maximizes the variance of the data along that vector, while being orthogonal to all previous basis vectors.
Mathematically, these basis vectors are the eigenvectors of the covariance matrix (also called loadings or weights).
The following plot shows data in two dimensions (the activity of two neurons) and an orthonormal basis that would:
Explain the most variance in the data with the first basis.
Reduce correlations in the data.
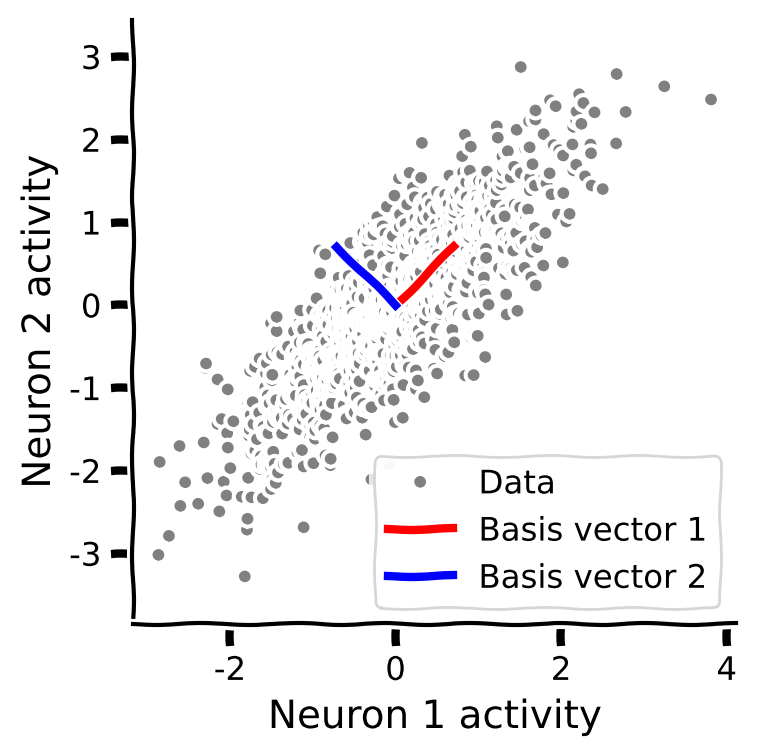
After using PCA to find the “eigenvectors” of the “covariance matrix” for a set of data, we can project that data onto the eigenvector basis set by doing the following matrix multiplication:
where \(\bf X\) is the original data (an \(N_\text{samples} \times M_\text{variables}\) matrix), \(\bf Y\) is an \(N_\text{samples} \times M_\text{features}\) matrix representing the projected data in the PCA space (also called scores), and \(\bf W\) is an \(N_\text{variables} \times N_\text{features}\) “transformation” matrix (also called weights or loadings). The “variables” are the dimensions of the original data. With PCA, the “features” are the intrinsic dimensions of highest variability in the data.
Executing the following code cell will enable an Interactive Demo in which you can examine the result of PCA projection of population spike rates (two neurons) onto two “projection basis vectors”. You can control the correlation between the neurons’ spiking activity. The Interactive Demo plots show:
Top: The original “neuron” space.
Note that in the line plots, the sample number is sorted based on the value of neuron 1’s activity (from lowest to highest) for each datapoint.
Bottom: The PCA space.
#@title Interactive Demo 1
#@title {display_mode:form}
#@markdown Execute this cell to enable the interactive demo
def refresh(corr_coef=0.5):
# corr_coef=0.5
variance_1 = 1
variance_2 = 1
# Compute covariance matrix
cov_matrix = calculate_cov_matrix(variance_1, variance_2, corr_coef)
# Generate data with this covariance matrix
X = get_data(cov_matrix)
# Perform PCA on the data matrix X
score, evectors, evals = pca(X)
W = evectors
# Plot the data projected into the new basis
# with plt.xkcd():
# plot_data_new_basis(Y)
fig = plt.figure(figsize=[20, 10])
gs = fig.add_gridspec(4, 4)
ax1 = fig.add_subplot(gs[0, 0])
ax1.plot(X[:, 0], color='k')
plt.ylabel('Neuron 1')
plt.title('Sample var 1: {:.1f}'.format(np.var(X[:, 0])))
ax1.set_xticklabels([])
ax2 = fig.add_subplot(gs[1, 0])
ax2.plot(X[:, 1], color='k')
plt.xlabel('Sample Number')
plt.ylabel('Neuron 2')
plt.title('Sample var 2: {:.1f}'.format(np.var(X[:, 1])))
ax3 = fig.add_subplot(gs[0:2, 1])
ax3.plot(X[:, 0], X[:, 1], '.', markerfacecolor=[.5, .5, .5],
markeredgewidth=0)
ax3.plot([0, W[0, 0]], [0, W[1, 0]], color='r', linewidth=3,
label='Basis vector 1')
ax3.plot([0, W[0, 1]], [0, W[1, 1]], color='b', linewidth=3,
label='Basis vector 2')
ax3.axis('equal')
plt.xlabel('Neuron 1 activity')
plt.ylabel('Neuron 2 activity')
plt.title('Correlation: {:.1f}'.format(np.corrcoef(X[:, 0], X[:, 1])[0, 1]))
# plot_data_new_basis(score)
Y = score
ax4 = fig.add_subplot(gs[2, 0])
ax4.plot(Y[:, 0], 'r')
plt.ylabel('Principal Component 1')
ax5 = fig.add_subplot(gs[3, 0])
ax5.plot(Y[:, 1], 'b')
plt.xlabel('Sample number')
plt.ylabel('Principal Component 2')
ax6 = fig.add_subplot(gs[2:4, 1])
ax6.plot(Y[:, 0], Y[:, 1], '.', color=[.5, .5, .5])
ax6.axis('equal')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('Correlation: {:.1f}'.format(np.corrcoef(Y[:, 0], Y[:, 1])[0, 1]))
plt.show()
_ = widgets.interact(refresh, corr_coef=(-1,1,0.1))
Notice that the eigenvectors (the dimensions of the new basis set) align with the intrinsic geometry of the data.
PCA also has the useful property that the projected data (scores) are uncorrelated in the new basis.
Section 2: Explained variance¶
Here, you can examine the magnitudes (eigenvalues) of the eigenvectors calculated by PCA and how that relates to the geometry and variance of the data. Remember that each eigenvalue describes the variance of the data projected onto its corresponding eigenvector (basis). This is an important concept because it allows us to rank the PCA basis vectors based on how much variance each one can capture.
For example, in the following scatter plot, the eigenvectors (“principal components”/orthonormal basis) of a random dataset have been computed by PCA and overlaid on the scatter. The first eigenvector (principal component 1) is plotted in red and the second eigenvector (principal component 2) is plotted in blue. The eigenvalues of each eigenvector (principal component) are shown in the scree plot right.
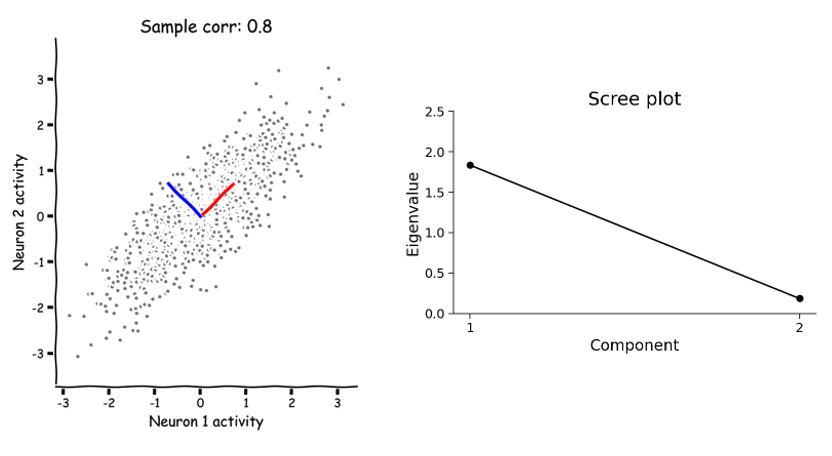
How do the eigenvectors and eigenvalues change as the geometry of a multivariate dataset changes? Remember that the correlation coefficient is one parameter that influences its intrinsic geometry.
What happens to the eigenvalues as you change the correlation coefficient?
Can you find a value for which both eigenvalues are equal?
Can you find a value for which only one eigenvalue is nonzero?
The following code cell runs an Interactive Demo to explore these questions.
#@title Interactive Demo 2
#@markdown Execute this cell to enable the interactive demo.
def plot_eigenvalues(corr_coef=0.8):
variance_1 = 1
variance_2 = 1
cov_matrix = calculate_cov_matrix(variance_1, variance_2, corr_coef)
X = get_data(cov_matrix)
score, evectors, evals = pca(X)
W = evectors
fig = plt.figure(figsize=[10, 6]);
gs = fig.add_gridspec(1,3)
# plot_basis_vectors(X, evectors)
ax1 = fig.add_subplot(gs[0, 0:2])
ax1.plot(X[:, 0], X[:, 1], '.', color=[.5, .5, .5])
ax1.axis('equal')
ax1.set_xlabel('Neuron 1 activity')
ax1.set_ylabel('Neuron 2 activity')
ax1.plot([0, W[0, 0]], [0, W[1, 0]], color='r', linewidth=3,
label='Principal Component 1')
ax1.plot([0, W[0, 1]], [0, W[1, 1]], color='b', linewidth=3,
label='Principal Component 2')
plt.axis('equal')
ax1.legend()
# plot_eigenvalues(evals)
ax2 = fig.add_subplot(gs[0, 2])
ax2.plot(np.arange(1, len(evals) + 1), evals, 'o-k')
ax2.set_xlabel('Component')
ax2.set_ylabel('Eigenvalue')
ax2.set_title('Scree plot')
ax2.set_xticks(np.arange(1, len(evals) + 1))
ax2.set_ylim([0, 2.5])
plt.show()
_ = widgets.interact(plot_eigenvalues, corr_coef=(-1, 1, .1))
Section 3: Dimensionality reduction by PCA.¶
Now let’s consider data that has a higher dimensionality. For example, the activity of 1000 neurons. We can’t visualize that like we have been because on a computer screen we can only visualize two dimensions (or 3 with an interactive rotating plot). We can perform PCA on the 1000-dimensional data just like we have been on 2-dimensional data. Instead of 2 eigenvectors, PCA would result in up to 1000.
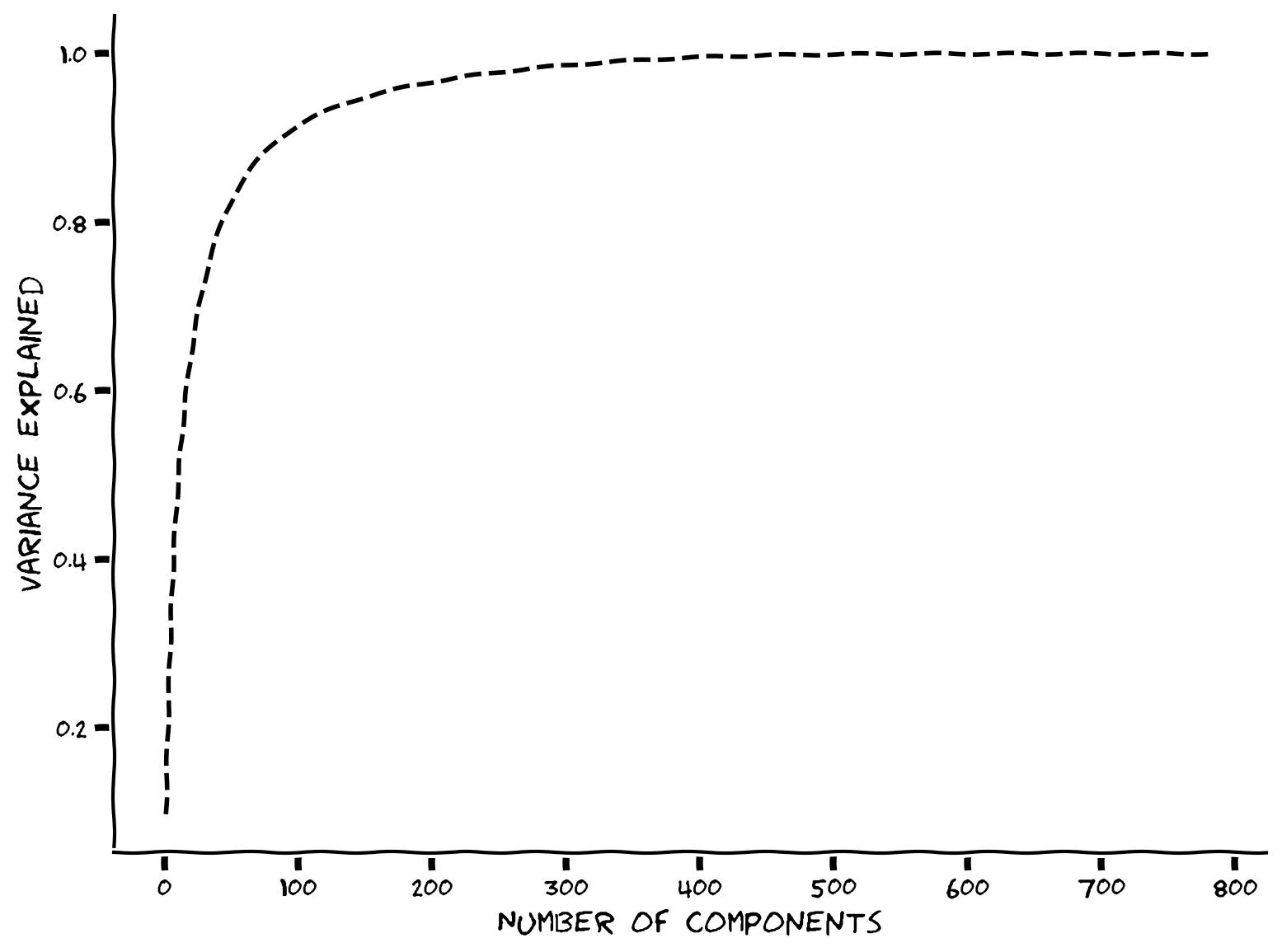
But here is where PCA becomes particularly useful and conceptually significant. In the example scree plot below, most of the eigenvalues are near zero, with fewer than ~50 having large values (only the first 100 components out of 1000 total are shown).

Based on this distribution of eigenvalues, we can understand something about the intrinsic dimensionality of the data… that the geometry is less than 50 dimensions, and can be pretty accurately described in as few as 10.
The intrinsic dimensionality of data is defined by the eigenvectors necessary to explain a large proportion of the total variance of the data (often a defined threshold, e.g., 90%). Therefore, to determine the data’s intrinsic dimensionality we look at the variance (proportional to the eigenvalues) explained by the components of the PCA (the eigenvectors). A cumulative plot is useful for visualizing the fraction of the total variance explained by the top \(K\) components. For example, in the plot below we see that just 100 components (eigenvectors from PCA) almost fully describe the 1000-dimensional data.
Click here if you are interested in detials about the math behind calculating the total variance explained
\begin{align} \text{var explained} = \frac{\sum_{i=1}^K \lambda_i}{\sum_{i=1}^N \lambda_i} \end{align}where \(\lambda_i\) is the \(i^{th}\) eigenvalue and \(N\) is the total number of components (the original number of dimensions in the data).
In the next couple of weeks, we will encounter specific examples of the utility of this concept in neuroscience.
Summary¶
In this tutorial, we learned that The goal of PCA is to find an orthonormal basis capturing the directions of maximum variance of the data. More precisely, the \(i\)th basis vector is the direction that maximizes the projected variance, while being orthogonal to all previous basis vectors. Mathematically, these basis vectors are the eigenvectors of the covariance matrix (also called loadings).
PCA also has the useful property that the projected data (scores) are uncorrelated.
The projected variance along each basis vector is given by its corresponding eigenvalue. This is important because it allows us rank the “importance” of each basis vector in terms of how much of the data variability it explains. An eigenvalue of zero means there is no variation along that direction so it can be dropped without losing any information about the original data.
Importantly, neuroscientists use this property to reduce the dimensionality of high-dimensional data.
Notation¶
This tutorial was written by Krista Perks for BIOL358 Motor Systems taught at Wesleyan University. Based on content from Neuromatch Academy 2020: Week 1, Day 5: Dimensionality Reduction by Alex Cayco Gajic, John Murray
Unused¶
# @markdown Execute this code cell to plot a new set of data (the activity of two neurons)
# @markdown with correlation coefficient 0.8
corr_coef=0.8
# corr_coef=0.5
variance_1 = 1
variance_2 = 1
# Compute covariance matrix
cov_matrix = calculate_cov_matrix(variance_1, variance_2, corr_coef)
# Generate data with this covariance matrix
X = get_data(cov_matrix)
# Perform PCA on the data matrix X
score, evectors, evals = pca(X)
W = evectors
# Plot the data projected into the new basis
with plt.xkcd():
# plot_data_new_basis(Y)
fig = plt.figure(figsize=[10, 6])
gs = fig.add_gridspec(2, 2)
ax1 = fig.add_subplot(gs[0, 0])
ax1.plot(X[:, 0], color='k')
plt.ylabel('Neuron 1')
plt.title('Sample var 1: {:.1f}'.format(np.var(X[:, 0])))
ax1.set_xticklabels([])
ax2 = fig.add_subplot(gs[1, 0])
ax2.plot(X[:, 1], color='k')
plt.xlabel('Sample Number')
plt.ylabel('Neuron 2')
plt.title('Sample var 2: {:.1f}'.format(np.var(X[:, 1])))
ax3 = fig.add_subplot(gs[0:2, 1])
ax3.plot(X[:, 0], X[:, 1], '.', markerfacecolor=[.5, .5, .5],
markeredgewidth=0)
ax3.plot([0, W[0, 0]], [0, W[1, 0]], color='r', linewidth=3,
label='Basis vector 1')
ax3.plot([0, W[0, 1]], [0, W[1, 1]], color='b', linewidth=3,
label='Basis vector 2')
ax3.axis('equal')
plt.xlabel('Neuron 1 activity')
plt.ylabel('Neuron 2 activity')
plt.title('Sample corr: {:.1f}'.format(np.corrcoef(X[:, 0], X[:, 1])[0, 1]))
plt.show()
Next, run the code below to plot the eigenvalues of the eigenvectors for thsi dataset (sometimes called the “scree plot”). Which eigenvalue is larger?
# @markdown Execute this cell to plot the eigenvalues for the new basis calculated by PCA on the data above
plot_eigenvalues(evals)